
当前主流的AI技术是Hiton、Lecun、Bengio等学者带来的深度学习,深度学习自诞生以来正在改变着很多行业,如安防、金融和物联网等。深度学习的兴起有海量数据和大算力两个支撑点。早期算力支撑主要由GPU提供,GPU具有支持高并行计算、访存速度快和浮点运算能力强等优点,比较符合深度学习的计算要求。但GPU设计的初衷是加速3D图形处理的通用芯片,并不是针对深度学习设计的,其计算功耗比(每瓦功耗的算力)这一指标并不突出。
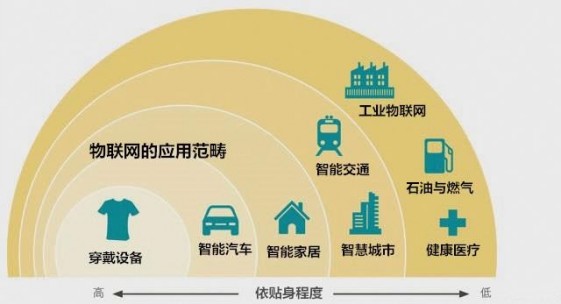
如果把目光聚焦到端AI,GPU计算功耗比低的弱点就更明显了。端AI应用的特点就是只做神经网络前向计算,不做反向传播,对运行时存储的要求不高,GPU显存大的优势体现不出来。穿戴式设备因为体积小等原因,对功耗非常敏感,同时由于要与人互动,穿戴式设备一般要求能实时运行神经网络模型。尽管网络模型可以裁剪,但为了保证模型的性能下降在可接受的范围,裁剪后的模型计算量仍然会比较大,这就要求端AI芯片有较强的算力。为了提高运行神经网络模型的计算功耗比,专用的端AI芯片就应运而生了。由于专用的AI芯片在一开始设计时就针对神经网络计算加速做优化,其性能提升往往能够突破摩尔定律,每隔18~24个月性能可提升5倍甚至更多。
当前主流端AI芯片有DSP形态和NPU形态两种。Intel movidius myraid2、高通Hexagon DSP都属于DSP形态的AI芯片。DSP的优势是工艺成熟,成本较低,每瓦功耗的算力可达100Gflops。华为麒麟970/980芯片、苹果A12芯片等则集成了NPU支持端AI计算,每瓦功耗算力可达500G-1T flops。NPU的计算功耗比相对DSP有较大的优势,是端AI芯片发展的趋势。Intel Movidius myraidX已经集成了NPU,相比myraid2每瓦功耗的算力提升了5倍以上。高通预计也将在2019年推出集成NPU的AI芯片。
当前,AI芯片算力提升的一个瓶颈是存储墙问题。在传统的冯诺伊曼架构下,计算单元和存储单元是分离的,深度学习模型运行时需要把数据从DDR内存搬移到计算单元内部存储里。数据搬移需要的功耗在整个计算中占非常大的比重,而且数据搬移的效率不会因为摩尔定律的发展而提高,这被称之为“存储墙”。当前解决“存储墙”问题的一个主要方案是3D堆叠技术,即在处理器周围堆叠更多的存储器件。
对用户来说,拥有一款端AI芯片还只是第一步,怎样在AI芯片上做应用开发才是关键。AI芯片公司通过提供专门的工具使得芯片对端AI应用开发透明。Intel提供OpenVINO工具包,高通提供NPE引擎,华为提供HiAI移动计算平台,都是为了支持用户无感地部署、运行神经网络模型,将AI芯片算力转化为生产力。业界领先的AR眼镜公司亮亮视野也推出了自己的Laffe框架,帮助用户用Movidius VPU的AI算力实现自己的价值。
 甘公网安备 62010202002440号
甘公网安备 62010202002440号


